Inline LLM code completions in VSCode without GitHub Copilot


For the past couple of years since GitHub Copilot was in private beta, I've been using the tool for both professional and personal projects. Recently with the proliferation of "open source" LLMs, like with Meta's latest model, Llama 3, it has become increasingly possible for developers and organizations to run and host their own Copilot-like tools.
I truly believe that Copilot is a great tool (withstanding the license/intellectual property shakiness that it is built on top of) and greatly increases productivity. I especially like it since it automates repetitive tasks. Sometimes I have to type out boilerplated JSON when developing in JavaScript; Copilot has proven to be extremely useful to me in recognizing patterns like that and then suggesting the next several lines with amazing accuracy. Copilot also has been great for helping me quickly write out code in an unfamiliar programming language. Sometimes I have to write a moderately complex Bash script. With a simple inline comment like # Loop over all args after the first one, it is able to usually suggest a snippet that shifts in the first argument to the script and sets up a loop in Bash, something that I still don't remember how to do. Lastly, with a descriptive comment, it is also just able to suggest entire blocks of otherwise uninteresting code.
While I've enjoyed using Copilot, it isn't without its problems and how it fits into my workflow. One is intellectual property; when writing code in a commercial setting, it varies greatly from organization to organization on if and how Copilot is allowed to be used. Some blanket ban in the name of keeping a tight reign on IP, and some allow through the purchase and use of enterprise Copilot licenses. Some code, no matter organization preference, also cannot be transmitted to an external server in the name of sensitivity of that code or adjacent information.
Self-hosted LLMs
After doing some quick searches, I was quickly able to find that there is an abundance of:
- Tools to run and self-host LLMs, usually in a format that reflects OpenAI's APIs.
- LLMs that fit in the memory of machines with ample resources.
- LLMs that run in a respectable and useful amount of time with the resources of an appropriately sized machine.
- LLMs that, given the speed and memory constraints, still manage to produce useful and relevant output.
- LLMs that are tuned for code completion and generation given instructions.
This is great news to me and really surprised me; when I had done some research on LLMs around half a year ago, I didn't remember encountering any of these tools or fine-tuned models (but perhaps I just wasn't looking in the right places). I ran into a fair amount of difficulty trying to get these to run as well and ultimately gave up.
Integrating a self-hosted LLM with VSCode
Note: this should work with any IDE/text editor that supports completion and chat from OpenAI.
I also largely adapted the steps below from this Medium article by Simon Fraser, which opened my eyes to this avenue.
Hardware
I am working on an M3 Mac with 36gb of RAM and ample storage (you shouldn't need more than 10gb to spare). You'll need a dedicated graphics card and enough memory to host the models in order to do efficient inference from an LLM.
Instructions
It is surprisingly easy to get a LLM running locally with Ollama. Ollama is a tool that manages the download, serve, and CLI tools to inference from LLMs. I'll be focusing mainly on the first two.
Ollama

To get up and running quickly:
- Download and install Ollama from here.
- Mac: You can install with Brew:
brew install --form ollama
- Mac: You can install with Brew:
- Open a shell and download some LLMs.
- I have had good experimental success with the codeqwen models, which you can pull via the commands below:
ollama pull codeqwen:chat- Pull a Qwen model tuned for a ChatGPT-like question-and-answer interface.ollama pull codeqwen:code- Pull a Qwen model tuned for inline code completion.- I recommend pulling both.
- You can browse the available models here: https://ollama.com/library
- I have had good experimental success with the codeqwen models, which you can pull via the commands below:
- As long as you have Ollama running, it is serving inference API endpoints on
http://localhost:11434
VSCode
Now, to integrate Ollama with VSCode:
- Open VSCode and install the Continue extension; see their website here: Continue.dev
- When Continue asks for how you'd like to set it up, select self-host or advanced.
- If you skipped this, you can also bring up the settings from in the Continue panel, click the gear in the bottom of the panel to bring up the settings.
- Under
models, configure Continue so it knows to get models from Ollama:

- And then under
tabAutocompleteModel, configure it to use the completion-tuned model,codeqwen:code:

- You may have to refresh VSCode at this point (
Cmd + Shift + P -> "Developer: Reload Window") - In the Continue pattern, at the bottom, select the
codeqwen:chatmodel so ensure that Continue uses the chat-tuned model for the chat window. - Now test it out! Ask questions in the Continue panel, or try out Continue/Ollama/the model in an open source code file.
- When you have code selected,
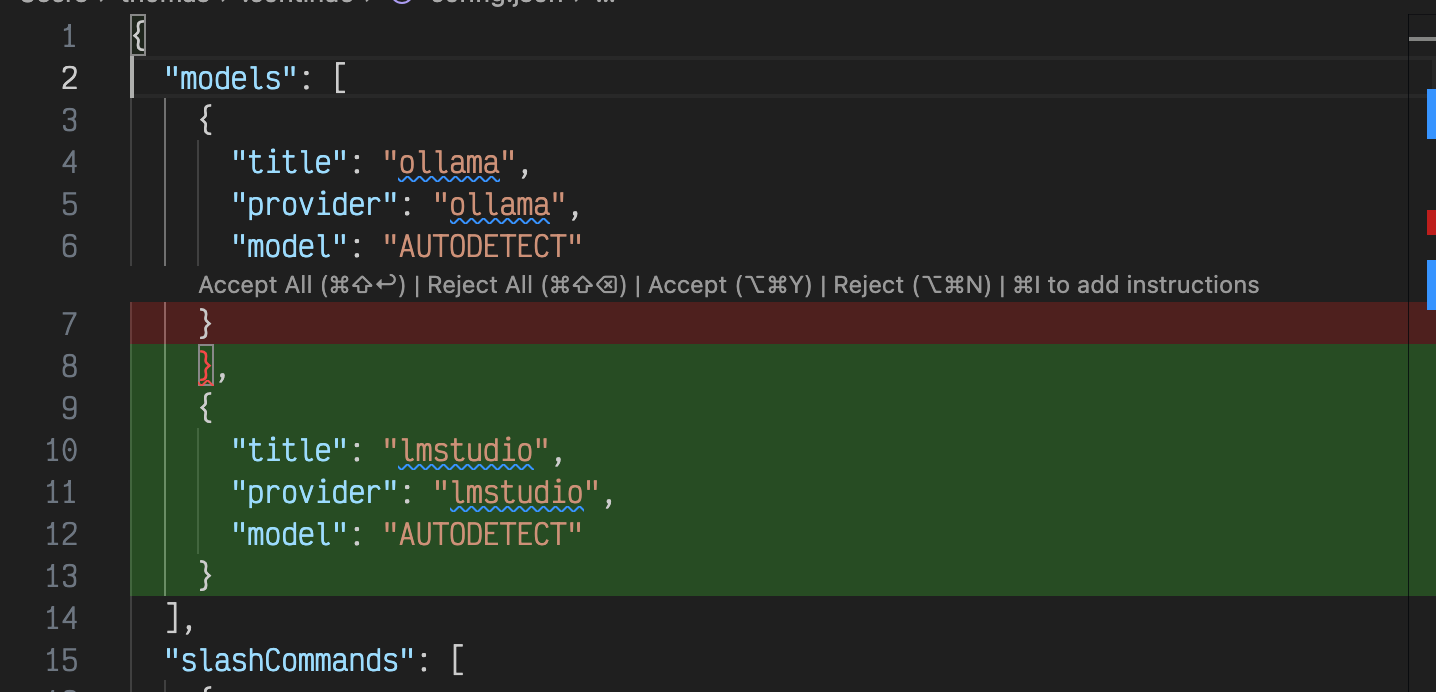
Cmd + Lallows you to ask questions about that code in the Continue panel, andCmd + Iallows you to inline edit that code given a prompt.- For example, in my Continue settings, I selected the
modelssection, hitCmd + I, and enteredAdd a model for lmstudio, which resulted in the following diff:
- For example, in my Continue settings, I selected the
- When you have code selected,
Trying out different models
Ollama makes many models available. You can access non-coding LLMs for general LLM inference from the CLI. There's also an abundance of larger and smaller models than the codeqwen models I used. I haven't tested larger models, but after comparing a lot of similar 7b parameter code models, I got mixed results. The codegemma models didn't perform well and just output junk for inline completions, for example.